Sistema de Control de Calidad de Datos Meteorológicos
Motivaciones
La necesidad de contar con un banco de datos meteorológicos
validados y completos para todos los objetivos que se llevan a
cabo en CIOMTA y su disponibilidad para otros organismos, es una
de las motivaciones principales del presente sistema.
La fiabilidad de los datos meteorológicos
resulta primordial para todas las aplicaciones, modelos agronómicos
y estudios científicos que de ellos dependen.
Por ejemplo, modelos de simulación de rendimiento de cultivos,
como el Cropsyst, se basan, entre otros, en los datos meteorológicos
y necesitan series históricas completas y consistentes
de datos diarios de por lo menos 30 años.
Objetivos
Lo expresado anteriormente condujo a la decisión de armar
una base de datos que centralice la información de nuestra
zona de estudio, lo más completa posible, cuyos datos pasen
por un control de calidad, y que además se siga alimentando
en forma continua y su consistencia pueda mejorarse día
a día con el refinamiento de los métodos a partir
de los resultados obtenidos y la experiencia acumulada.
Descripción del trabajo
Para el logro de esa base mencionada, vital
para nuestro sistema integrado, fue necesario trabajar con dos
categorías de datos:
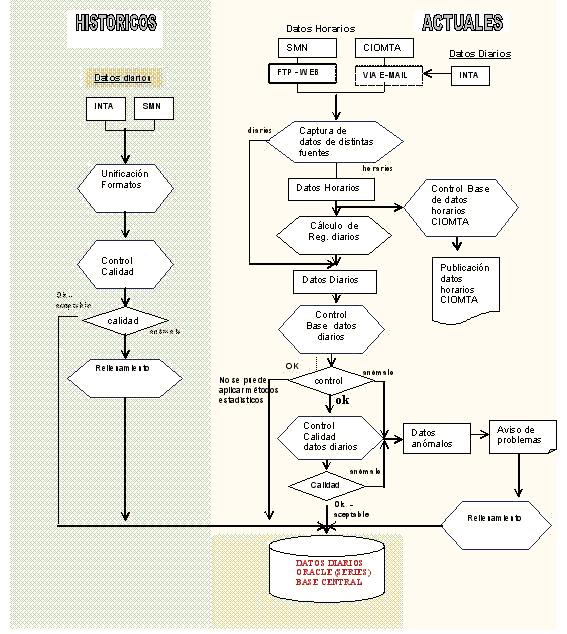
- DATOS HISTORICOS
Dentro de esta categoría se encuentran las series históricas
de datos meteorológicos diarios del INTA y del SMN y que
cuentan con registros de más de 30 años.
Como primer paso fue necesario homogeneizarlas bajo un mismo formato
a fin de poder darles un tratamiento sistemático. Luego
se procedió a agrupar las estaciones según su pertenencia
a zonas climatológicamente homogéneas (necesario
para los análisis de correlación areal).
Subsistema de control de calidad
de series históricas y generación de faltantes
Seguido a esto se elaboró un software con el fin de poder
asignarle a cada dato un “flag” o marca que permita
calificarlo de “bueno”, “aceptable” ,
“anómalo” o “faltante” como resultado
de la aplicación de tres métodos estadísticos
convenientemente seleccionados que verifican la consistencia respecto
a las fuentes de variabilidad interanual (variación del
dato registrado en un momento del año en una serie anual,
o sea en distintos años), temporal (variación del
dato respecto al valor precedente o sucesivo) y espacial (variación
del dato medido en un momento en distintas estaciones).
Si ninguno de los métodos lo encuentra sospechoso, el datos
será calificado como “bueno”. Si uno o dos
métodos indican como sospechoso, el dato se considera “aceptable”.
Si los tres métodos coinciden en tildarlo como sospechoso,
el dato pasa a la categoría de “anómalo”,
para su posterior rellenamiento (junto a los datos faltantes).
Terminada la clasificación, el programa
procede a la generación de aquellos datos “anómalos”
y de los “faltantes” en los casos que no haya más
de 90 días seguidos de ausentes (o menos dependiendo la
variable), y se aplica un método de rellenamiento que ha
sido seleccionado, probado y verificado en nuestro centro (Ver
Análisis Series Históricas).
Este control se realizó sobre las variables Temperatura
Máxima, Temperatura Mínima y Precipitación.
Para el caso de la Radiación global diaria se utilizaron
otros métodos para estimarla, que varían según
los datos de entrada disponibles.
Estas series históricas, una vez procesadas fueron cargadas
a la base central ORACLE del sistema integrado.
- DATOS ACTUALES
Se consideran datos actuales a todos aquellos que se reciben diariamente
desde diferentes fuentes (CIOMTA, INTA, SMN) en tiempo operativo.
Como estos registros deben seguir alimentando las series en forma
continua, se diseñó un Sistema automático
que los capture, les realice los controles de validación,
los califique, impute los ausentes y finalmente los deposite en
la base de datos (en ORACLE).
Origen de los datos recibidos
Datos de las estaciones CIOMTA
Cada estación meteorológica del CIOMTA registra
datos en forma horaria y en base a éstos calcula los datos
diarios para cada variable (temperatura del aire y del suelo,
dirección y velocidad del viento, precipitación,
humedad, presión y radiación solar) con sus máximos,
mínimos y acumulados respectivamente. Estos se envían
vía satélite a una estación terrena. Esta
última es la encargada de reenviarlos a una cuenta de correo
electrónico del CIOMTA. (Ver
Estaciones Meteorológicas CIOMTA)
Datos del SMN
EL Servicio meteorológico Nacional almacena datos horarios
en archivos txt (temperatura ,humedad, Veloc. del Viento , dirección
del viento ,presión , estado del cielo, visibilidad y sensación
térmica) y dos variables diarias: heliofanía y precipitación,
en una cuenta FTP.
Datos del INTA
El INTA envía achivos txt de datos diarios por mail en
forma esporádica (temperatura máxima, temperatura
mínima, temperatura media, precipitación, humedad,
radiación global y velocidad del viento).
Descripción del Sistema
de Control de Calidad de datos meteorológicos actuales
Captura automática
El sistema captura los datos horarios mediante una lectura automática
de mensajes de correo electrónico enviados por estaciones
del CIOMTA y de archivos que se obtienen de la Web o de un servidor
particular, en el caso del SMN. Desde allí los coloca en
dos repositorios externos según sean horarios o diarios.
Los datos horarios del CIOMTA reciben un primer control de Base
a medida que van llegando y se publican en www.ciomta.com.ar/datos.html.
Los datos horarios del SMN se utilizan para calcular los datos
diarios, que son volcados al repositorio de datos diarios y que
sirve como resguardo de los datos originales.
Control de base y control de calidad de los datos diarios
A continuación el sistema lee los datos meteorológicos
diarios almacenados en la tabla recién mencionada y los
somete a una serie de controles básicos que permiten descartar
a aquellos que aparecen como valores imposibles.
Si la variable tiene serie histórica, es posible hacer
controles más finos basados en análisis estadísticos.
En el caso de la temperatura y de la precipitación, se
hace también un control de calidad mediante una adaptación
de los métodos desarrollados para los datos históricos
(considerando al dato actual como uno más de su serie histórica).
La calificación surge como resultado de aplicar todos los
controles posibles (rutinas asociadas a cada tipo de variable)
y se guarda en un campo destinado para cada variable denominado
flag (bandera). Que puede tomar los siguientes valores:
| FLAG |
DESCRIPCION |
| 0 |
dato correcto |
| >0 y < 1 |
dato aceptable |
| 1 |
dato erróneo |
| 2 |
dato faltante |
Los datos clasificados como anómalos o faltantes son almacenados
en otra tabla a fin de analizar los problemas y emitir avisos para
analizar las causas de los mismos.
Rellenamiento
Para los casos cuya marca o flag sea 1 o 2, automáticamente
son procesados por una rutina de rellenamiento, que devuelve el
valor generado para la variable y reasigna el flag (valor 3) para
indicar que el dato ha sido rellenado.
En caso de no poder estimarse la variable por alguna de las siguientes
causas:
- problemas de discontinuidades muy grandes en las series
- zonas climáticas que no cumplen con el mínimo de
estaciones (3) que presenten un periodo en comun con la suficiente
cantidad años para poder aplicar el método.
- o tratarse de variables que no tienen asociado ningún algoritmo
que permita su generación
El dato se calificará con un 6 que indica que no pudo estimar.
Almacenamiento
Como último paso de su recorrido, el dato es almacenado
en la Base Oracle, alimentando la serie historica.




